
中国唯一一家专业只做ARACLE认证和BDA实训的甲骨文金牌合作企业
中国唯一一家专业只做ARACLE认证和BDA实训的甲骨文金牌合作企业








Hadoop培训教程:HDFS升级和回滚机制,作为一个大型的分布式系统,Hadoop内部实现了一套升级机制,当在一个集群上升级Hadoop时,像其他的软件升级一样,可能会有新的bug或一些会影响现有应用的非兼容性变更出现。在任何有实际意义的HDFS系统中,丢失数据是不允许的,更不用说重新搭建启动HDFS了。当然,升级可能成功,也可能失败。如果失败了,那就用rollback进行回滚;如果过了一段时间,系统运行正常,那就可以通过f?inalize正式提交这次升级。相关升级和回滚命令如下:
bin/hadoop namenode -upgrade // 升级
bin/hadoop namenode -rollback // 回滚
bin/hadoop namenode -f?inalize // 提交
bin/hadoop namenode -importCheckpoint // 从Checkpoint恢复
上述命令的importCheckpoint参数用于NameNode发生故障后,从某个检查点恢复。HDFS允许管理员退回到之前的Hadoop版本,将集群的状态回滚到升级之前。在升级之前,管理员需要用以下命令删除已存在的备份文件:
bin/hadoop dfsadmin –f?inalizeUpgrade // 升级终结操作
下面简单介绍一下一般的升级过程。
在升级Hadoop软件之前,检查是否已经存在一个备份,如果备份存在,可执行升级终结操作删除这个备份。通过以下命令能够知道是否需要对一个集群执行升级终结操作:
dfsadmin -upgradeProgress status
1)停止集群并部署Hadoop的新版本。
2)使用-upgrade选项运行新的版本(bin/start-dfs.sh -upgrade)。
在大多数情况下,集群都能够正常运行。一旦我们认为新的HDFS运行正常(也许经过几天的操作之后),就可以对其执行升级终结操作。需要注意的是,在对一个集群执行升级终结操作之前,删除那些升级前就已经存在的文件并不会真正地释放DataNode上的磁盘空间。
如果需要退回到老版本,执行步骤如下:
1)停止集群并部署Hadoop的老版本。
2)用回滚选项启动集群,命令如下:
bin/start-dfs.h -rollback
上面介绍了HDFS升级和回滚的基本机制,其实可以从状态转移的角度来理解HDFS的升级和回滚机制。整个HDFS的状态有:Normal,Upgraded,Rollbacking,Upgrading,Finalizing五种,HDFS集群的状态转移示意图,如图3-8所示。
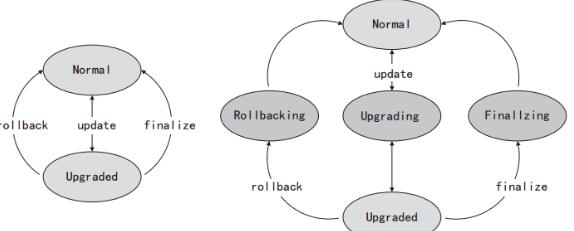
从图3-8中可以看出,升级、回滚、提交都不可能一下完成,这也就是说,在HDFS系统出现故障时,集群可能处于图3-8右侧图中某一个状态中。特别是在分布式的各个节点上,甚至可能出现有些节点已经升级成功,但有些节点可能处于中间状态的情况,所以Hadoop采用类似于数据库事务的升级机制也就很容易理解了。
CUUG 优技培训
 CUUG -CHINA UNIX USER GROUP,是国际UNIX组织UNIFORUM的中国代表,是国内悠久的专业UNIX培训机构,被誉为中国UNIX 的摇篮。
CUUG -CHINA UNIX USER GROUP,是国际UNIX组织UNIFORUM的中国代表,是国内悠久的专业UNIX培训机构,被誉为中国UNIX 的摇篮。金牌讲师
实操环境
院校合作
学校新闻
行业新闻

请输入您的手机号
申请试听






